[1] Glow: Generative Flow with Invertible 1×1 Convolutions
Diederik P. Kingma, Prafulla Dhariwal
OpenAI, Google AI
流式生成模型(Dinh et al. 2014)在概念上具有吸引性,有以下几个原因,它能处理精确的对数似然度,能处理精确的隐变量推理,还可以并行处理训练和合成。
这篇文章提出了Glow,这是一种简单的生成式流式模型,该模型利用可逆的1×1卷积。这种方法在基准数据集上在对数似然度方面取得了显著的提升。令人吃惊的是,流式生成模型利用一般的对数似然度目标优化时,可以高效地合成和变换近似真实的大图片。
基于似然度的方法可以分为以下三类
基于流的生成方法具有以下特性
本文所提模型图示如下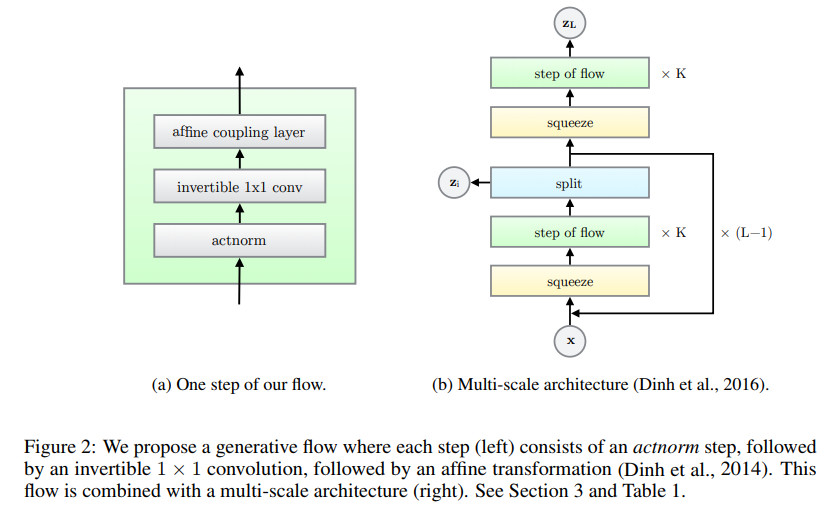
本文所提流的三个主要组成部分,逆以及对数行列式统计如下
三种方法的效果对比如下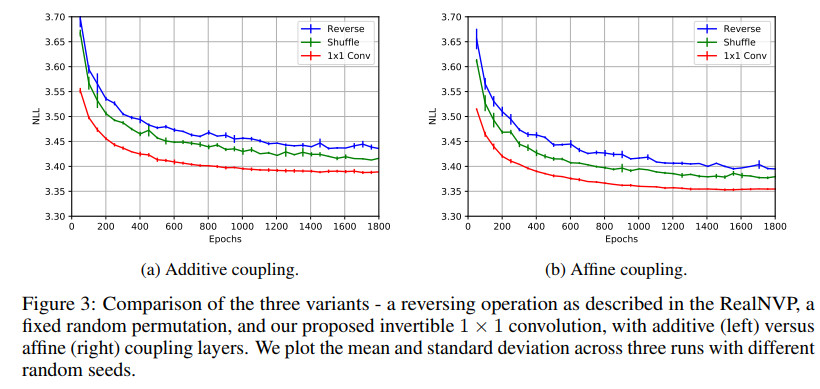
几种方法在不同数据集上的效果对比如下
其中RealNVP对应的论文为
Dinh, L., Sohl-Dickstein, J., and Bengio, S. (2016). Density estimation using Real NVP. arXiv preprint arXiv:1605.08803.
代码地址
https://github.com/tensorflow/models/tree/master/research/real_nvp
https://github.com/taesungp/real-nvp
代码地址
https://github.com/openai/glow
[2] Robustness of conditional GANs to noisy labels
Kiran Koshy Thekumparampil, Ashish Khetan, Zinan Lin, Sewoong Oh
University of Illinois at Urbana-Champaign, Carnegie Mellon University
这篇文章主要研究如何从带有噪声标签的样本中学习条件生成器,这里的带噪声标签是指标签由随机噪声污染了。条件GANs的标准训练方法不仅会生成带有错误标签的样本,而且会生成质量较差的样本。
根据噪声模型是否已知可以分为两张场景。当噪声分布已知时,本文提出一种新的结构,称为鲁棒条件GAN (RCGAN)。其主要思想在于在传入对抗判别器之前,对生成样本的标签施加干扰,迫使生成器产生干净标签的样本。这种在匹配噪声通道传播的方法由伴随的乘法近似界来解释,这种界是RCGAN的损失函数以及干净真实分布和生成器分布之间的距离得到的。这说明本文所提方法的判别器结构精心选择时,即映射判别器,该方法具有鲁棒性。
当噪声分布未知时,该结构可以进行扩展,简称RCGAN-U,该方法能够在训练判别器的同时学习噪声模型。在数据集MNIST和CIFAR-10上的实验表明两种方法都比基准方法有所提升,而且RCGAN-U的性能跟RCGAN的性能非常接近。
RCGAN的结构图示如下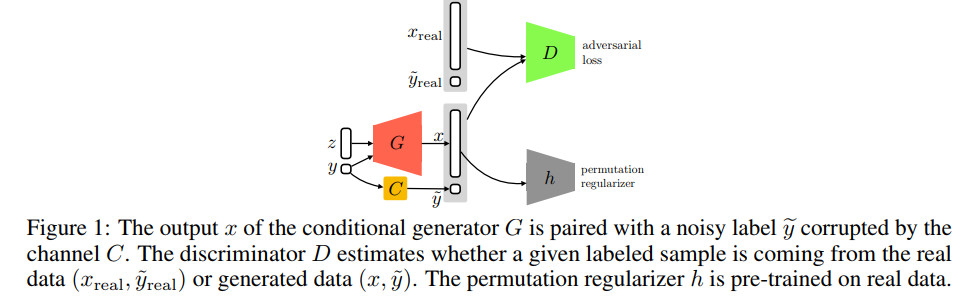
几种方法在数据集MNIST上的效果对比如下
几种方法在数据集CIFAR-10上的效果对比如下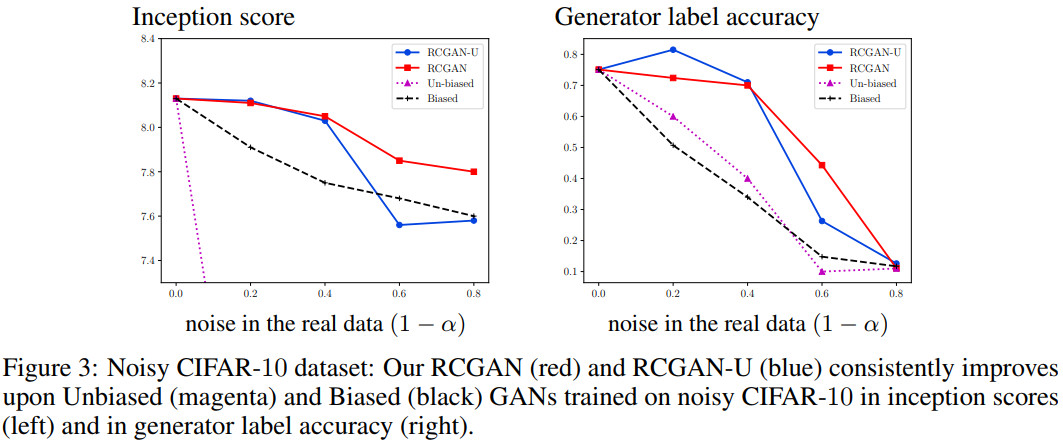
代码地址
https://github.com/POLane16/Robust-Conditional-GAN
https://github.com/wenxinxu/resnet-in-tensorflow
[3] Gaussian Process Prior Variational Autoencoders
Francesco Paolo Casale, Adrian V Dalca, Luca Saglietti, Jennifer Listgarten , Nicolo Fusi
Microsoft Research New England, MIT, Martinos Center for Biomedical Imaging, MGH, HMS, Italian Institute for Genomic Medicine, University of California, Berkeley (CA)
变分自编码在通过无监督方式学习复杂数据分布中是一种效果较好并且广泛应用的模型。变分自编码中一个重要的限制在于其关于样本的隐含表示是独立同分布的。
然而,很多重要的数据集,比如图像时间序列,该假设太强了:这些样本之间的协方差在时间上可以生成更合适的模型,而且可以提升下游任务的性能。
这篇文章提出一种新的模型,高斯过程先验的变分自编码(GPPVAE),可以解决上述问题。GPPVAE能够将VAE的效果和GP先验对相关性的建模能力结合起来。为了使得这种新模型的推理比较高效,该文作者对协方差矩阵的结构进行了调整,并且给出一种新的随机反向传播策略,该策略能够以分布式并且低内存的方式来计算随机梯度。
在两个图像数据集上的效果表明该方法不仅优于条件变分自编码(CVAEs),并且优于另外一种VAE的变种。
GPPVAE的结构及过程图示如下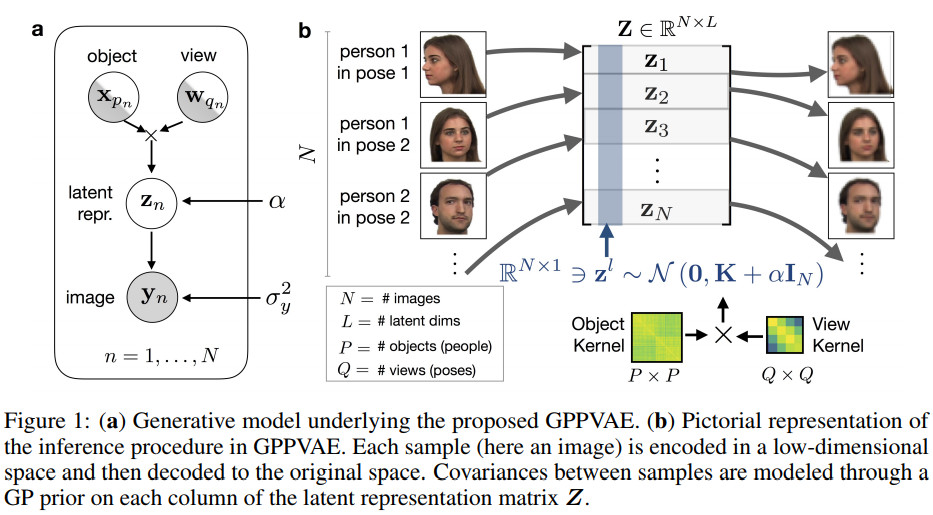
该算法的主要步骤如下
![]()
几种方法在数据集MNIST上的效果对比如下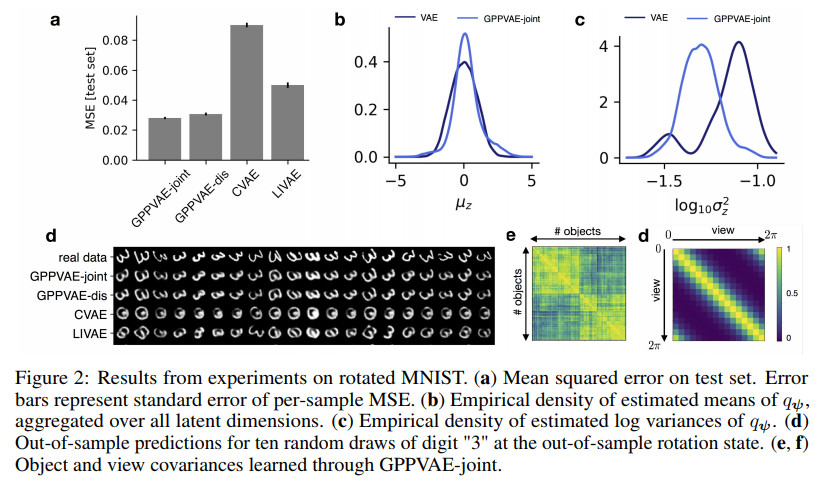
几种方法在人脸数据集上的效果对比如下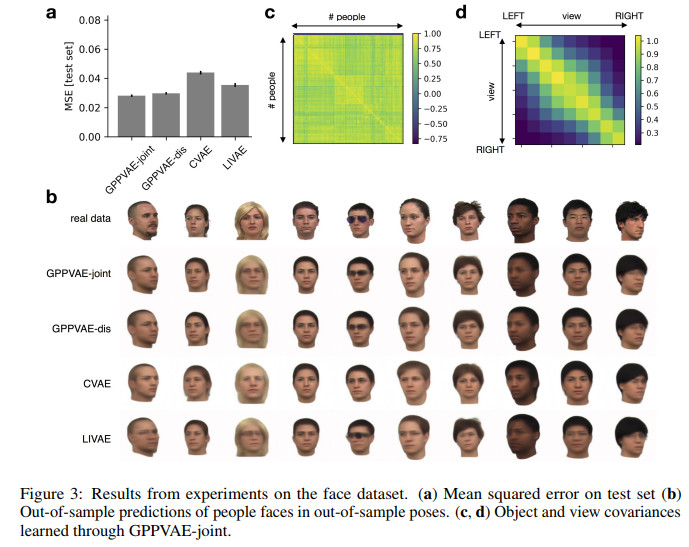
实验中涉及的几种方法解释如下
CVAE对应的论文为
Learning structured output representation using deep conditional generative models. NIPS 2015
代码地址
https://github.com/hujinsen/pytorch_VAE_CVAE

代码地址


文章评论