[1] Structure-Aware Convolutional Neural Networks
Jianlong Chang, Jie Gu, Lingfeng Wang, Gaofeng Meng, Shiming Xiang, Chunhong Pan
Chinese Academy of Sciences, University of Chinese Academy of Sciences
这篇文章提出一种可以适用于具有一定结构的卷积神经网络,这种网络不仅可以处理欧氏距离的数据,也可以处理非欧氏距离的结构化数据。结构卷积算子可以将多种拓扑结构的数据聚合起来,并且利用函数逼近理论使得卷积滤波具有有限个需要学习的参数。该网络简称为SACNNs。
这篇文章的主要贡献如下

能够处理结构化数据的卷积图示如下
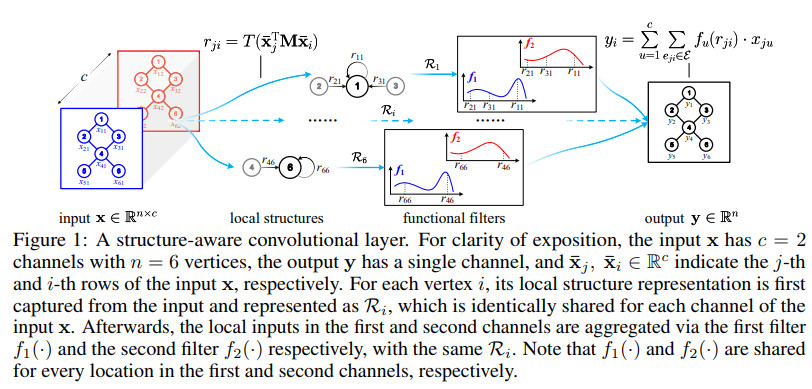
几种方法在多个数据集上的效果对比如下
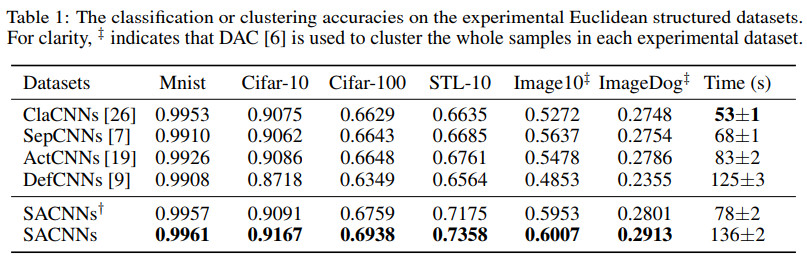
其中ClaCNNs为classical convolution,即卷积神经网络鼻祖Yann Lecun提出的原始的卷积神经网络;
SepCNNs为separable convolution,论文见 Xception: Deep learning with depthwise separable convolutions, CVPR 2017;
ActCNNs为active convolution,论文见Active convolution: Learning the shape of convolution for image classification,CVPR 2017;
DefCNNs为deformable convolution,论文见Deformable convolutional networks,ICCV 2017。
几种方法的不变性对比如下

几种方法在非欧几里得距离数据集上的效果对比如下
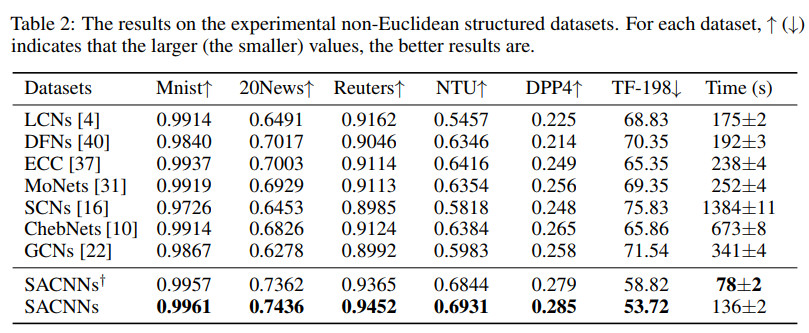
其中LCNs为local connected networks,论文见Spectral networks and locally connected networks on graphs, ICLR 2014;
DFNs为dynamic filters based networks,论文见FeaStNet: Feature-Steered Graph Convolutions for 3D Shape Analysis,CVPR 2018;
ECC为edge-conditioned convolution,论文见Dynamic edge-conditioned filters in convolutional neural networks on graphs,CVPR 2017;
MoNets为mixture-model networks,论文见Geometric deep learning on graphs and manifolds using mixture model cnns,CVPR 2017;
SCNs 为spectral networks,论文见Deep convolutional networks on graph-structured data,2015;
ChebNets为Chebyshev based SCNs,论文见Convolutional neural networks on graphs with fast localized spectral filtering,NIPS 2016;
GCNs为graph convolution networks,论文见Semi-supervised classification with graph convolutional networks,ICLR 2017;
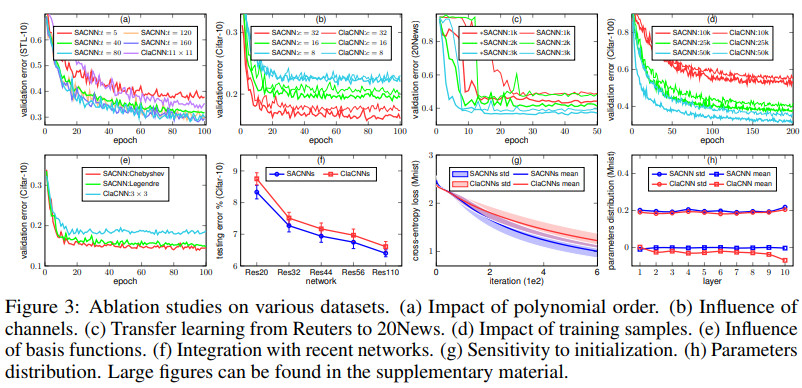
多种情况下几种方法的效果对比如下
代码地址
https://github.com/vector-1127/SACNNs
[2] Text-Adaptive Generative Adversarial Networks: Manipulating Images with Natural Language
Seonghyeon Nam, Yunji Kim, and Seon Joo Kim
Yonsei University
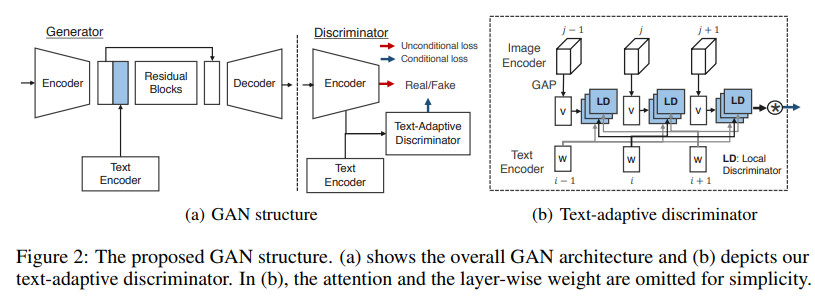
这篇文章主要讨论如何利用自然语言来改变图像。具体而言即为,通过文本描述在语意上来改变物体的视觉属性。这篇文章所提出的模型是GAN的一种衍生模型,该模型是文本自适应的,优势在于可以不影响跟文本无关的内容。这种方法的关键在于文本自适应的判别器,该判别器可以根据输入文本生成字符级别的局部判别器,进而对各个细粒度的属性进行独立的分类。只有文本对应的图像会发生变化,同时保持文本无关的部分不会发生变化。
本文所提方法的效果可视化示例如下

网络整体结构示例如下
几种方法的效果对比如下
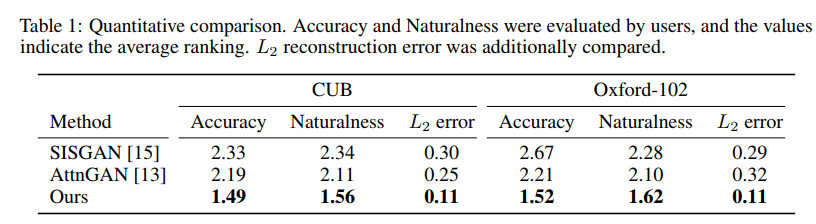
其中SISGAN对应的论文为Semantic image synthesis via adversarial learning,ICCV 2017;
AttnGAN对应的论文为Attngan: Fine-grained text to image generation with attentional generative adversarial networks,CVPR 2018
本文所提方法在部分数据集上的效果示例如下

几种方法的效果对比如下

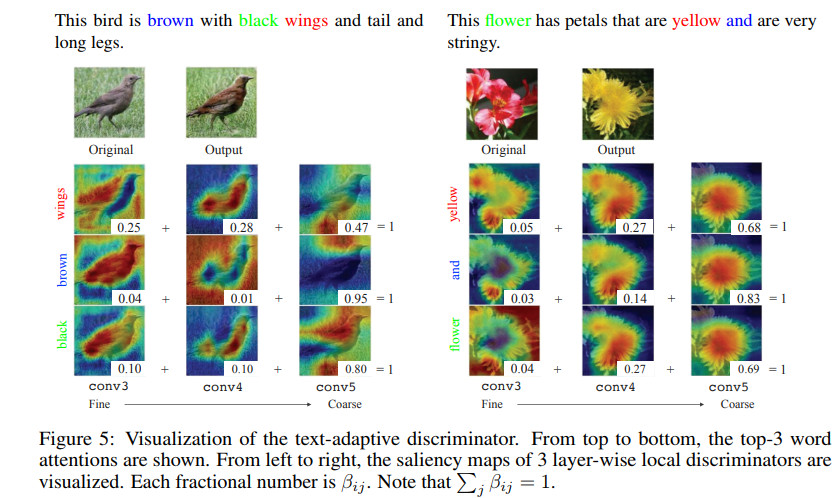
文本自适应判别器示例如下
在多模态检索任务中几种方法的效果对比如下

其中34对应的论文为Learning deep representations of fine-grained visual descriptions,CVPR 2016;
32对应的论文为Identity-aware textual-visual matching with latent coattention,CVPR 2017;
13对应的论文为Attngan: Fine-grained text to image generation with attentional generative adversarial networks, CVPR 2018
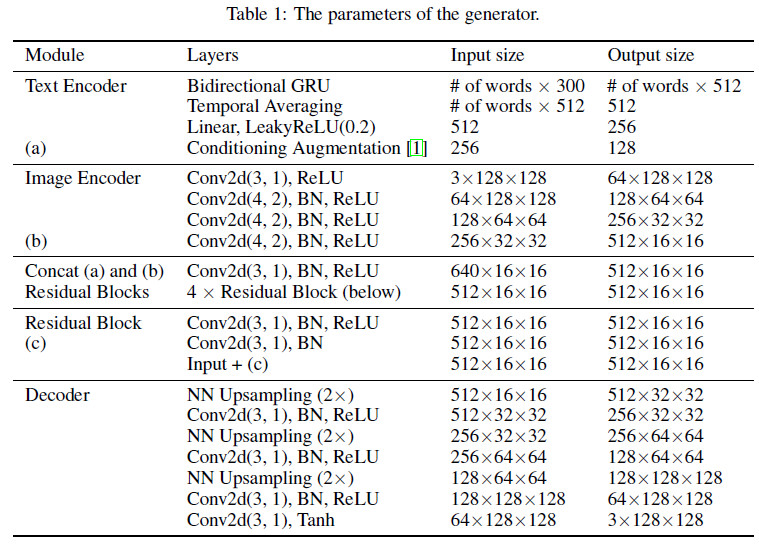
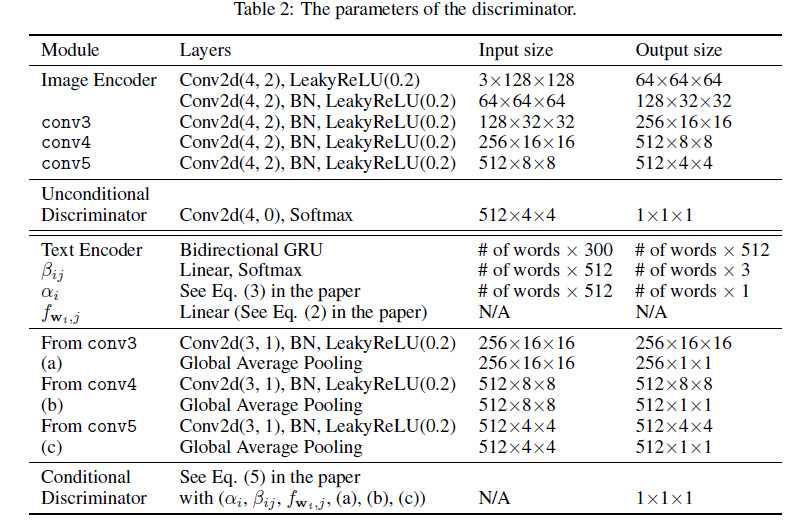
网络参数如下
代码地址
https://github.com/woozzu/tagan
[3] IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis
Huaibo Huang, Zhihang Li, Ran He , Zhenan Sun, Tieniu Tan
University of Chinese Academy of Sciences
这篇文章提出一种新的变分自编码,内省变分自编码,该模型可以合成高分辨率摄影图像。这种模型可以自我评估生成样本的质量,并且可以根据情况提升质量。该方法的推理和生成器模型是通过自省方式联合训练的。生成器能够从推理模型的噪声输出中对输入图像进行重构,这点跟一般的变分自编码类似。推理模型可以区分生成的图像和真实的图像,而生成器类似于GAN。这两种著名的生成式模型框架集成在一个高效结构中,在单阶段中即可训练。另外,该模型不需要额外的判别器,因为该模型中的推理模型自身就是一个判别器,该判别器可以区分生成的和真实的样本。
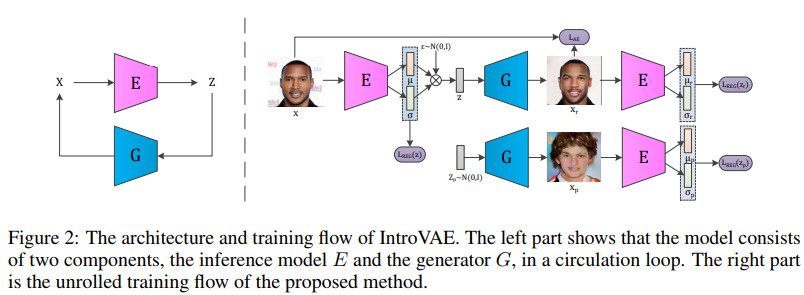
本文所提方法的结构及训练流程示例如下
训练模型的伪代码如下

训练速度与分辨率的组合对比如下

几种方法的效果对比如下

其中WGAN-GP对应的论文为Improved training of wasserstein GANs,NIPS 2017;
PGGAN对应的论文为Progressive growing of GANs for improved quality, stability, and variation,ICLR 2018
代码地址
https://github.com/moskomule/introvae.pytorch
[4] Adapted Deep Embeddings: A Synthesis of Methods for k-Shot Inductive Transfer Learning
Tyler R. Scott, Karl Ridgeway, Michael C. Mozer
University of Colorado
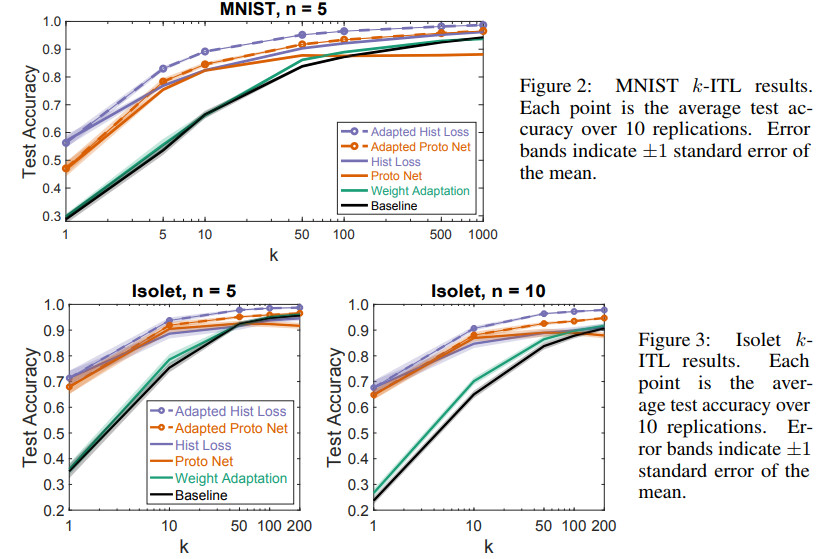
这篇论文主要探索混合自适应嵌入方法,该方法可以利用有限的目标域的数据来微调根据源域的数据所构建的嵌入。该论文的主要结论如下:
(1) 深层嵌入在域之间的迁移或模型复用层面相对加权迁移具有明显的优势,
(2)本文所提混合方法优于每个少数样本学习法和之前提出的深层度量学习法,均方差相对之前最好的方法可以降低34%
(3)在发现嵌入的损失函数中,直方图误差鲁棒性最好。
几个数据集中源数据和目标数据的分割示例如下

几种方法的效果对比如下
代码地址
https://github.com/tylersco/adapted_deep_embeddings
[5] Supervised autoencoders: Improving generalization performance with unsupervised regularizers
Lei Le, Andrew Patterson and Martha White
Indiana University, University of Alberta
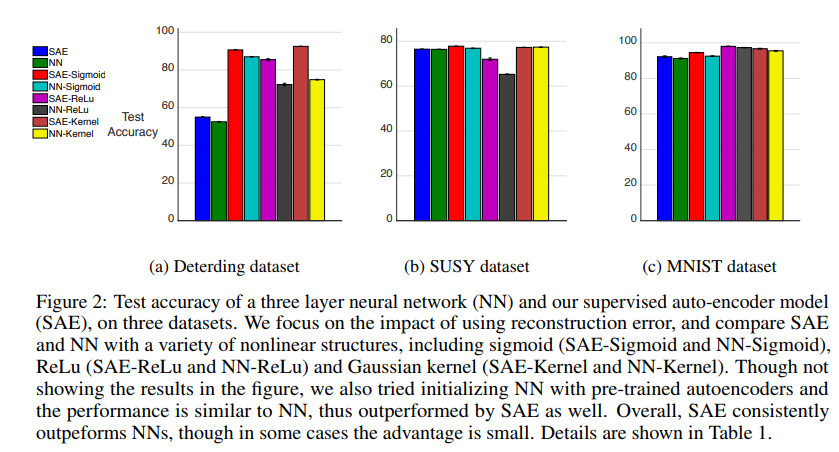
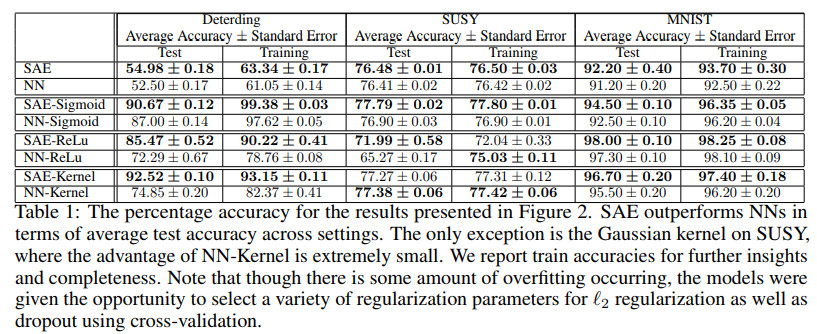
这篇文章分析了有监督自编码,这种网络可以同时预测标签和输入。作者对线性自编码进行了一种新的泛化,基于重构误差证明了一致稳定性,特别是对范数等简单正则的改进。针对不同的隐含单元数,激活函数等,有监督自编码相对标准神经网络不仅性能没有降低,而且可以提升泛化能力。
有监督自编码结构示例如下

几种方法的效果对比如下
后记:
这几年GAN、CNN是真的能玩出花来……


文章评论