[1] Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Kurtland Chua, Roberto Calandra, Rowan McAllister, Sergey Levine
University of California, Berkeley
基于模型的强化学习算法通常能够得到不错的采样效率,但是从渐近性能角度来讲,这种方法的效果一般比不上不用模型的算法。尤其是针对表达能力较高的含参函数逼近这种场景,比如深层网络。
这篇文章主要解决上述问题,该文的主要思想在于不确定性动态模型。作者们提出了一种新的算法,基于轨迹采样的概率集成算法,该算法记作PETS(probabilistic ensembles with trajectory sampling)。这种方法结合了不确定性深层网络动态模型和基于采样的不确定性传播。其主要优势在于需要非常少的样本即可得到挺好的效果。
pets流程示例如下
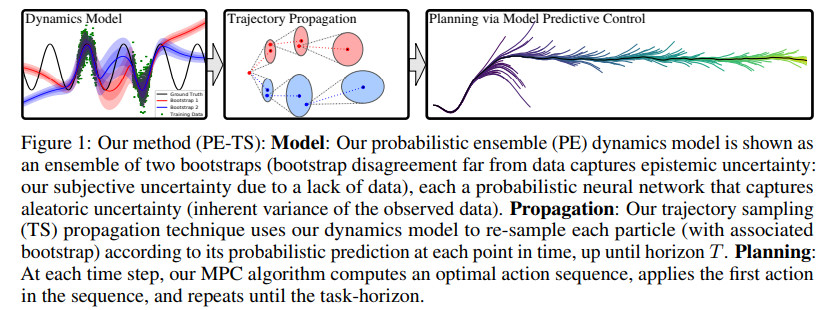
其中MPC全称为model predictive control,对应的文献为
E. F. Camacho and C. B. Alba. Model predictive control. Springer Science & Business Media, 2013.
本文所提出的算法是新的model-based reinforcement learning。
几种方法的不确定性对比如下

上图中两种不确定性的区别在于
aleatoric uncertainty是比较随机的,来源于系统的,而epistemic uncertainty带有主观性,是由数据有限造成的。
pets算法伪代码如下

其中CEM对应的文献为
Z. I. Botev, D. P. Kroese, R. Y. Rubinstein, and P. L’Ecuyer. The cross-entropy method for optimization. In Handbook of statistics, volume 31, pages 35–59. Elsevier, 2013.
CEM方法的特点在于从更接近先前行动的分布中采样,进而得到高回报。
多种方法在不同任务上的学习曲线对比如下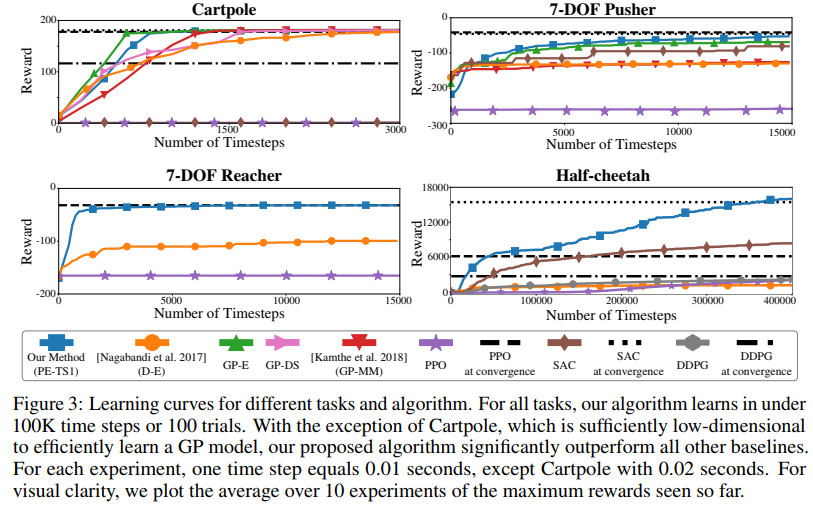
其中PPO为Proximal policy optimization
对应的代码实现见
Openai baselines. https://github.com/openai/baselines, 2017.
DDPG为Deep deterministic policy gradient
对应的代码实现见
Openai baselines. https://github.com/openai/baselines, 2017.
SAC为Soft actor critic
对应的文献为
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. ICML, 2018.
代码地址
https://github.com/haarnoja/sac
最终几种方法的效果对比如下
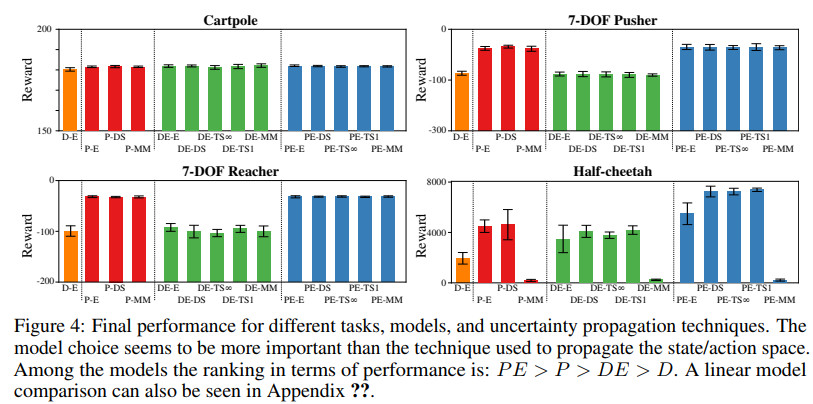
代码地址
https://github.com/kchua/handful-of-trials
[2] Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
Edoardo Conti, Vashisht Madhavan, Felipe Petroski Such, Joel Lehman, Kenneth O. Stanley, Jeff Clune
Uber AI Labs
很多强化学习问题都需要有向探索,因为其中的回报函数具有稀疏性或者包含局部最优值,如何利用进化策略来促使这些有向探索未可知。针对小规模进化神经网络,可以利用探索智能体来促进有向探索,比如新颖搜索和质量多样性算法。在稀疏或者具有局部最优解的深层强化学习任务中,这些算法跟进化搜索结合起来可以提高性能,同时可以保持扩展性。
这篇文章针对强化学习引入了一种快速可扩展的算法,该算法能够进行有向探索。
几种方法的效果对比如下
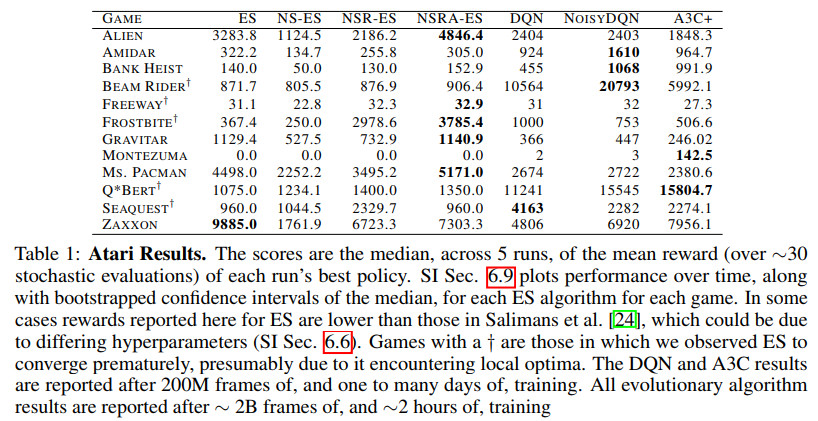
其中ES为Evolution Strategies
对应的论文为
Evolution strategies as a scalable alternative to reinforcement learning
代码地址
https://github.com/openai/evolution-strategies-starter
NS-ES算法伪代码如下

NSR-ES算法伪代码如下
NSRA-ES算法伪代码如下
NOISYDQN对应的论文为
Noisy networks for exploration
代码地址
https://github.com/Kaixhin/NoisyNet-A3C
A3C+对应的论文为
Unifying count-based exploration and intrinsic motivation. NIPS 2016
代码地址
https://github.com/uber-research/deep-neuroevolution
[3] Geometry-Aware Recurrent Neural Networks for Active Visual Recognition
Ricson Cheng , Ziyan Wang , Katerina Fragkiadaki
Carnegie Mellon University
这篇文章提出了循环几何神经网络,该网络将场景中的多个视角得到的视觉信息集成为三维的隐含特征张量。同时,在三维物理位置和隐含特征空间中的位置之间保持了一一映射。
对于输入的任意二维图像,利用构建的三维特征,可以进行目标检测、目标分割以及三维重建等。利用可微自运动特征变换和学习得到的深度反映射,可以在输入帧特征和构建的隐含模型之间得到几何一致的映射。
本文所提算法泛化性能相对不带几何结构的lstm/gru网络要好,尤其是有多个物体或者物体之间存在遮掩时。结合主动视角选取策略,该模型能够选取信息量大的点,进而将去除物体遮掩之后的信息融合进来,这样可以跟来自经验的几何信息无缝结合。
这篇文章的主要贡献在于

网络结构及流程示例如下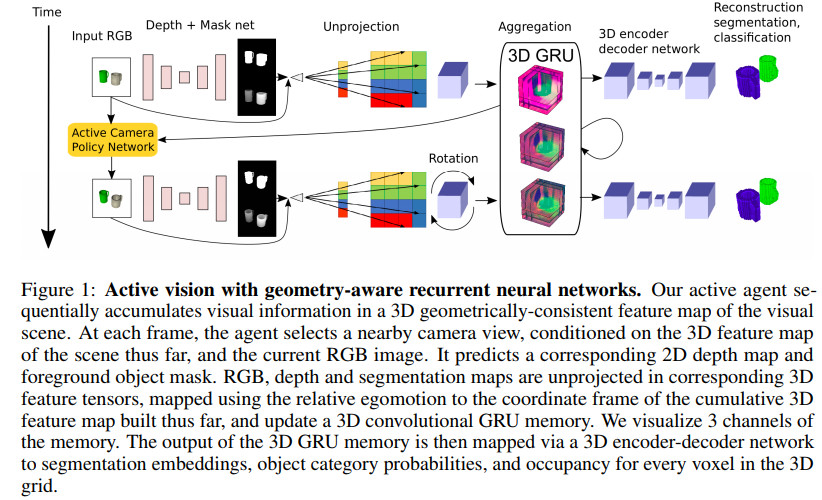
几种方法的效果对比如下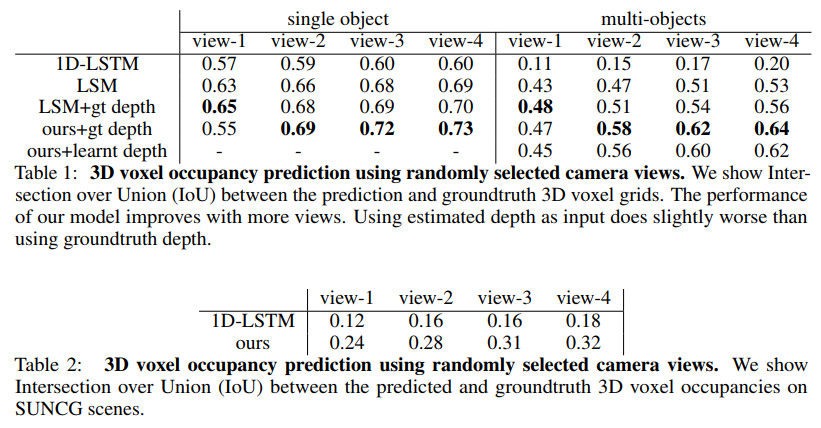
代码地址


文章评论